Hey backers,
I have so much to tell! I'm going to try to keep it nice and readable. Let's start with the typical monthly version release, this time brought to you almost single-handedly by Andrew Chou:
- 🎉 Feature: toggle in Settings to check for new versions
- ✅ (Desktop) Bug fix: top bar title selectable
- ✅ Bug fix: hashtags autocomplete is case-insensitive
- ✅ Bug fix: improve insertion of attachments in Compose
- ✅ Bug fix: Private draft when clearing and re-pasting
For those of you who read the last newsletter update, we are radically changing the nature of our work: we're building the next peer-to-peer protocol that can sustainably support (limited and/or) mobile devices forever. Let me share with you everything that has happened in March.
First of all, I was expecting some donations to be cancelled, due to the new direction. To my surprise, there have been more donations! Thank you so much! You believe in this and don't want to see it winding down.
SIPs
Knowing that I'd work on the protocol, I started collecting SSB specs in a centralized location, and the result is the SIPs repo in SSBC's GitHub. This is something we discussed at p2p-basel as well. SIP stands for Scuttlebutt Implementation Protocols and there are currently 9 of them. We hope we can collect and/or write more of these, which should benefit anyone trying to understand SSB!
Ideation begins
A month ago, I started exploring what are the requirements for the next protocol. Sustainable storage is obviously one of the core requirements, but it implies a "sliding window" replication system and a "garbage collection" system that deletes older messages. They all have to work together with the feed format (the "append-only feed" of data) to allow browsing content without disruptions, and to respect storage limits. We're focusing on getting these three components right before progressing to anything else.
I shared thoughts with arj03 and Geoffrey, who have similar wishes for the next protocol. arj03 already came up with very solid ideas for a feed format, minibutt. This spawned a lot of thoughts and questions and more proposals, so we're using these GitHub issues as a discussion forum, anyone is welcome to join the discussion!
Super simple 64MB database
One of the crazy ideas I had was guided by a goal of keeping storage restricted to maximum 100MB (this comes from estimates of how much free space people have on iPhones, typically competing with gigabytes of photos and videos). 100MB doesn't sound like a lot of data in RAM, so I considered a super simple persistence system where there is just one file, and then an in-memory database that has no indexes, you just operate on all the data in RAM! It sounded very naive at first, but I built a couple proof of concepts, including this SSB-compatible library, and after testing it in many scenarios, I am confident this is going to work.
At first, it may seem like too little data, but I made several calculations and estimations, and it's clear that you can follow hundreds of interesting people, replicating months worth of their content, and it should all fit in 64MB. The 64MB limit ended up becoming a guiding principle for the next protocol.
This has many interesting implications. First, it's a guarantee that this protocol will always run on consumer hardware, unlike SSB which increasingly needs more and more CPU, RAM, and Disk space, slowly entering the realm of Big Data and Surveillance Capitalism. Second, it makes an effort to forget the past, reducing some anxiety that exists on SSB that your content is permanent (there's a lot more to be said about this point, because some types of permanance and remembering are great). Third, 64MB is great for developers because they don't have to use or build advanced databases that are efficient, instead you can just naively load up everything in memory and do whatever you want, because the small scale of data makes most queries run quickly enough! Certainly quicker than the average HTTP request on the web.
Tangle sync? DAG sync?
Given that replication will be so important, we began looking into how the replication algorithm should work. At first, we revived discussions about "tangle sync" which is another name for "set reconciliation" championed by SSB's great researchers keks and Aljoscha. Read this paper for more context.
Geoffrey also had his own replication algorithm based on Bloom Clocks which I gave a careful read too. The requirements for the replication algorithm are:
- Must support "sliced replication" (fetching only the N latest, instead of everything)
- Must support synchronizing Directed Acyclic Graphs (DAGs)
- Must support cryptographically verifying adherence to the past
These requirements are surprisingly tough. Our hopes went up when we discovered Martin Kleppmann's Bloom Filter Hash Graph Sync algorithm, which is simple to implement and provides a great starting point to match those requirements above.
I went ahead and started implementing the algorithm, to get a closer understanding of its corner cases. It seems very promising!
Pruning the past
While replication concerns "fetching" new data, deleting old data is equally important. Some cases are easy to delete, for instance with emoji reactions, we can simply decide to delete all reactions older than N months. But other cases are harder. Consider the following case: two years ago, you followed Alice, then you changed your mind and unfollowed her. Now you have two pieces of data lying around, one for the follow and another for the unfollowed, but they neutralize each other, and the data is now meaningless. It would be good to automatically detect these irrelevant data pieces, so we know they can be safely deleted. We don't want to delete follow data just on the basis of it being old.
Gladly, an MSc student at the University of Basel wrote their thesis precisely on this topic. I got the PDF privately and it's not on the web yet, so I can't share it yet. But I implemented the ideas of the thesis in a proof of concept, and it seems like it's going to work and going to be useful.
Lipmaa Tangles
Back to replication, I was motivated by a problem in sliced replication and by recently working with Mix on a SIP for tangles. I considered the thought of dropping linear feeds where forking is fatal, and embracing tangles (a.k.a. DAGs) everywhere. After some exploration, I came up with a concept called Lipmaa Tangles which adds Bamboo's lipmaa links on top of any tangle.
I am probably speaking alien language to you right now, so let me zoom out a bit and help you understand what all this means.
A big problem with SSB right now is that you can't use the same identity on several devices, because this leads to forking, which means your account is broken and no one can get your updates anymore. Tangle feeds provide a way of gracefully recovering from forks, such that you could use the same identity on several devices.
However, we still want to delete old content, but we don't want to do that in a way that would lose cryptographic "ordering" of the message. Apologies for the technical terms, again. What this means is that we don't want to give other peers (potentially untrusted peers!) the opportunity to lie when they are giving you updated data for a feed you follow. When you get new data, you need to know that it was actually authored by the right account, and you need proof that this is the "next" piece that comes after the pieces you already have. So, somehow, we have to keep some old data around to be able to tie together new data with old data and prove that one came after the other. Otherwise we end up with a naive protocol like Nostr that allows relay servers to selectively censor content they don't like.
This is where the so-called "lipmaa links" come to the rescue. They're result of a PhD thesis that figured out a way of weaving new data with old data such that you don't have to keep all the old data, just keep a few important ones. Actually, very very few (technically, logarithmically few), which is great for our 64MB budget.
Now that you have some idea what I'm talking about, Lipmaa Tangles are a way of publishing data in the new protocol such that:
- You can publish from multiple devices with the same identity
- You can frequently delete old data
- You can cryptographically prove you published one thing after the other, preventing censorships and omissions
- You will never break your account with "forking"
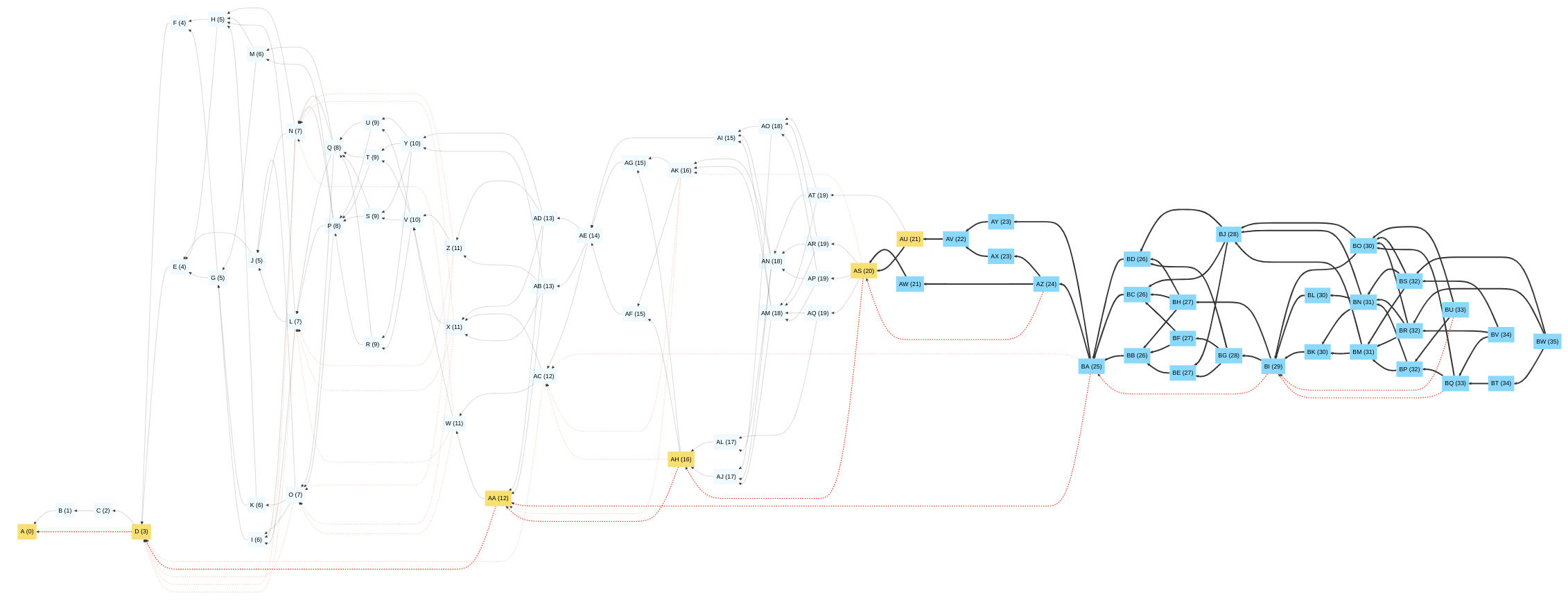
Isn't that exciting? Here's an example diagram of how it looks like:
Secret Handshake 2
Finally, a sort of side quest I had last month, is reworking Secret Handshake (the cryptographic handshake protocol SSB uses) so that it should support a better invite system. This is a necessary building block to implement the invite system that our designer Nicholas Frota has been working on in the past months. Anyway, Secret Handshake 2 was rather easy to build, as a tweak from version 1! I look forward to sharing its implementation later, when relevant.
Conclusion
To close up, I must say that all these protocol advancements are a significant departure from SSB, such that it's not worth calling it SSB anymore. I think that would end up causing too much confusion, and compatibility with the original SSB would always be a painful topic to address. So I have decided to create a new protocol project, with SSB as parent, and p2panda as older brother. I already have a name and a web domain, and a work-in-progress logo, but those are secrets for now.
Keep following this newsletter and I'll keep revealing more details. :)
– @andrestaltz