Hey backers,
This is an exciting newsletter update, because I can finally say that the new protocol (codename PPPPP) is validated and ready to be implemented. Last month, I worked on a tricky and important case in garbage collection (GC), and found a solution. In this update, I'll explain what the solution – called "ghosts" – is, as well as outlining what comes next during implementation phase.
For context, replication and garbage collection are both dictated by tracking "goals", a way of declaring for each tangle how much of it (or if any at all) you want to have in your database. For most cases, the goal of having the "latest" N messages is enough, allowing us to delete messages older than the latest N. However, last month I found a case where this is not enough. It is possible for garbage collection to be too eager or too lazy, leading to either deleting too early or preserving too much.
To implement an app like Manyverse in PPPPP, there would be different types of user data. The different types have different replication and GC treatment. For instance, a user's emoji reactions and their posts can be replicated and garbage collected as a "newest 1000" goal, such that we only keep the latest 1000 messages. Losing the past (or an alternative branch of the near past) is acceptable. This is not true for other types of user data, though.
As an example, the list of accounts you follow is a mathematical Set: you can add accounts to it and later remove them. So if you recently added someone to that list, it's not acceptable to forget about this addition. As much as possible, we want to guarantee that all Set additions are preserved while garbage collection does its job. In fact, there may be a lot of opportunity to remove useless information, because if you follow, unfollow, follow many times in a row, all that matters is the latest follow. Some part of the past is irrelevant, but other parts are indispensable. I'm using layman's terms here, but I'm talking about CRDTs.
Let's walk through a diagram example. Say you have a tangle of follow messages and have already deleted part of it. Bold blue are messages present in the database, and weak gray are messages that were deleted from the database.

You're only interested in replicating the latest 3 messages (from depth 3 to depth 5, or beyond), so let's show the depth of each message in the diagram.

So far so good, but if there is a new depth-2 message ("F") when replicating with another peer, you wouldn't fetch that message because its depth is too low since it doesn't land inside the "want range" of 3–5. "F" might be an important "follow" message.
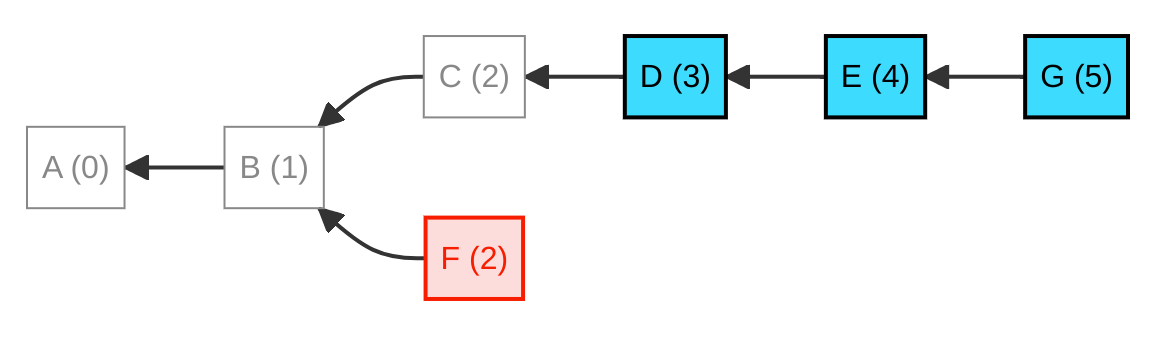
We could fix that by extending the "want range" to 2–5, but this has the adverse effect of re-fetching message "C" which we had already deleted (see below), and is useless to us. We're now in a dilemma, because we need to replicate "new" messages with depth less than 3, without re-fetching those that we have already deleted. The core problem is that after we delete a message, we also forget that we have ever had it in the first place!
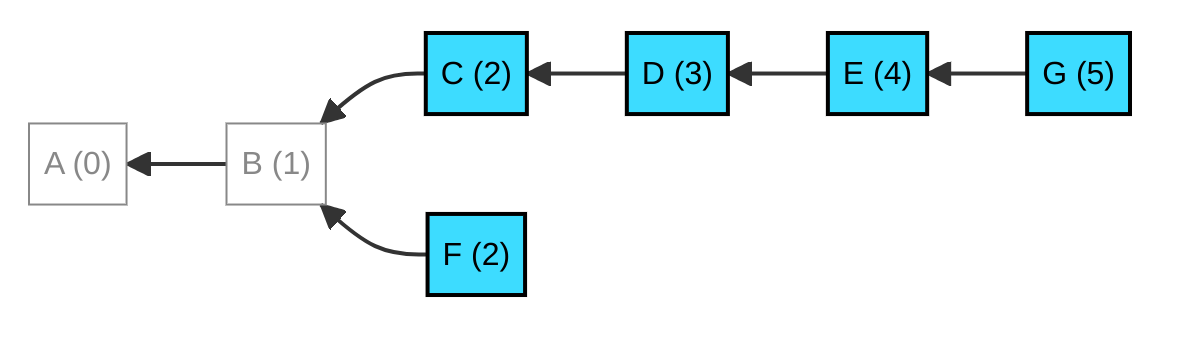
The solution is to not forget that the deletion took place. That is what a "ghost" is. It's a fancy name for a simple idea: a local file (or database index) that registers IDs of recently deleted messages, and their depth in the tangle. In the diagram below, purple messages are ghosts, i.e. effectively deleted, but their pre-existence remembered.
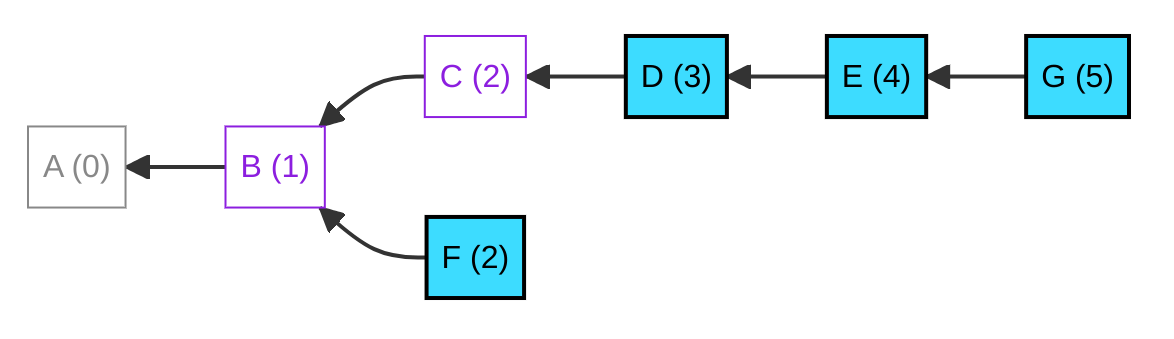
Now we can extend our "want range" to 1–5 and have a "ghost span" of depth 2, which covers ghost messages in depths 1 and 2. This allows us to discover new low-depth messages, such as "F", without re-fetching "B" and "C" which we had already deleted.
Ghosts are not an actual protocol concept, because they are just local information. But they make it easier to implement the garbage collection and replication parts of the protocol. During replication with a remote peer, you can register ghost message IDs in the exchanged bloom filter, as a way of telling the remote peer that you already have that message (or are not interested in fetching it). During garbage collection, the algorithm will determine whether to just delete a message, or to delete-and-ghost it.
The ghost registry itself is also "garbage collected", or "pruned" so that it doesn't grow indefinitely. (This is why in the example above, "A" is not a ghost because it has left the ghost registry.) Nothing should grow indefinitely in PPPPP. That's where "ghost span" is used: it gives an upper bound for many ghosts you're going to remember. If you set ghost span to 0, then you will never remember ghosts, and you will have to re-fetch deleted messages (or you'll accept ignoring newly-discovered past messages). If you set ghost span to 100, then you will remember a lot of ghosts, but you will also give up more storage space for ghost registries.
These parameters don't mean that PPPPP is strictly limited to a small database, it just means that we design the protocol to be "bounded everything", or in other words avoiding unbounded growth of anything. I truly believe that this is very important for a P2P protocol running on end-user devices. At a certain scale, on-device computing becomes a prohibitive practice. The parameters are there to select how much of computing resources you want to dedicate to PPPPP (in proportion to the hardware's limits or the user's wishes), instead of consuming all (or more) of it. The only unbounded growth allowed should be logarithmic (e.g. in lipmaa links in the tangle feed), which means it's ridiculously slow to scale and can be ignored for practical purposes.
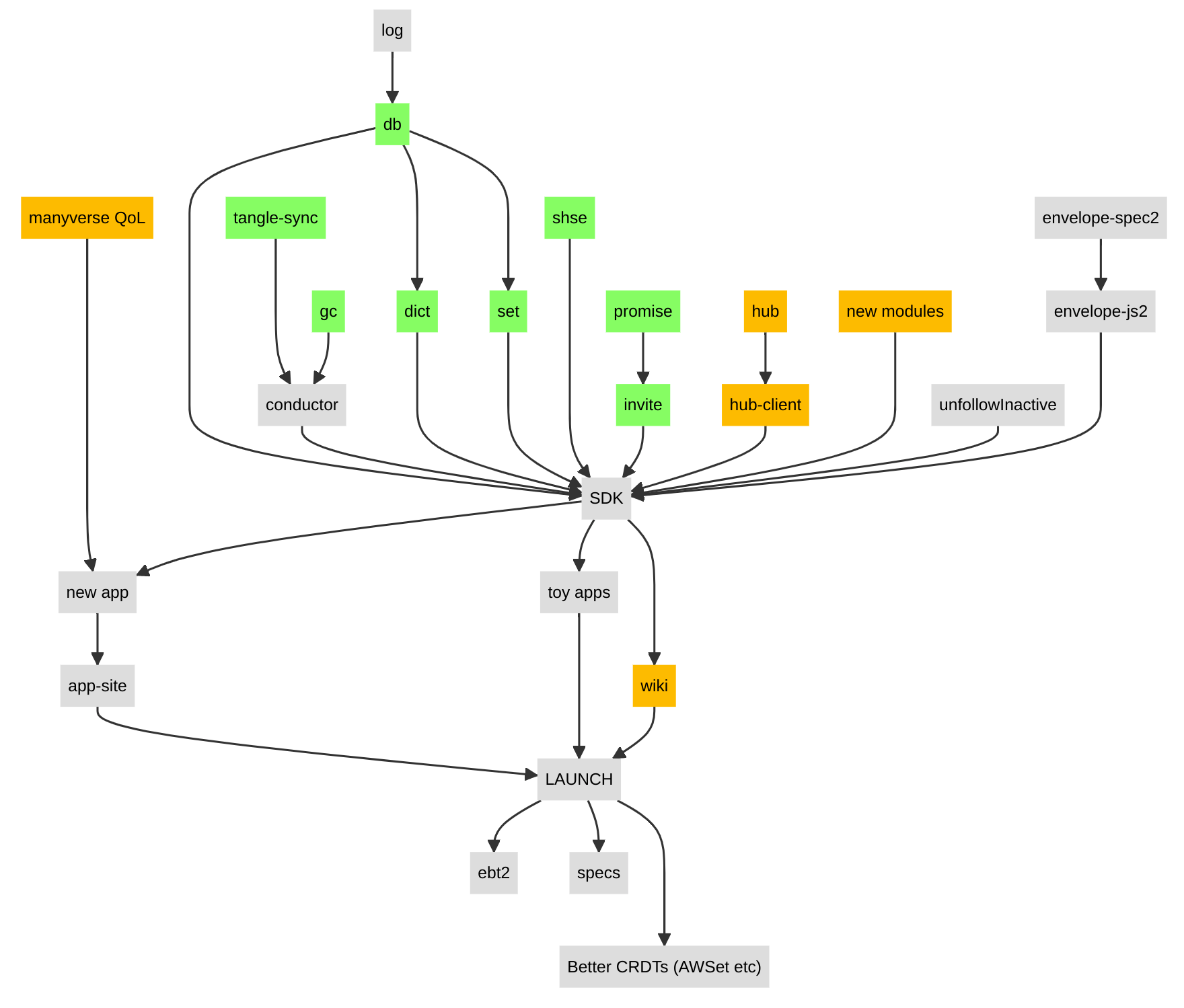
Lets take a look at the validation roadmap, which is now all green:
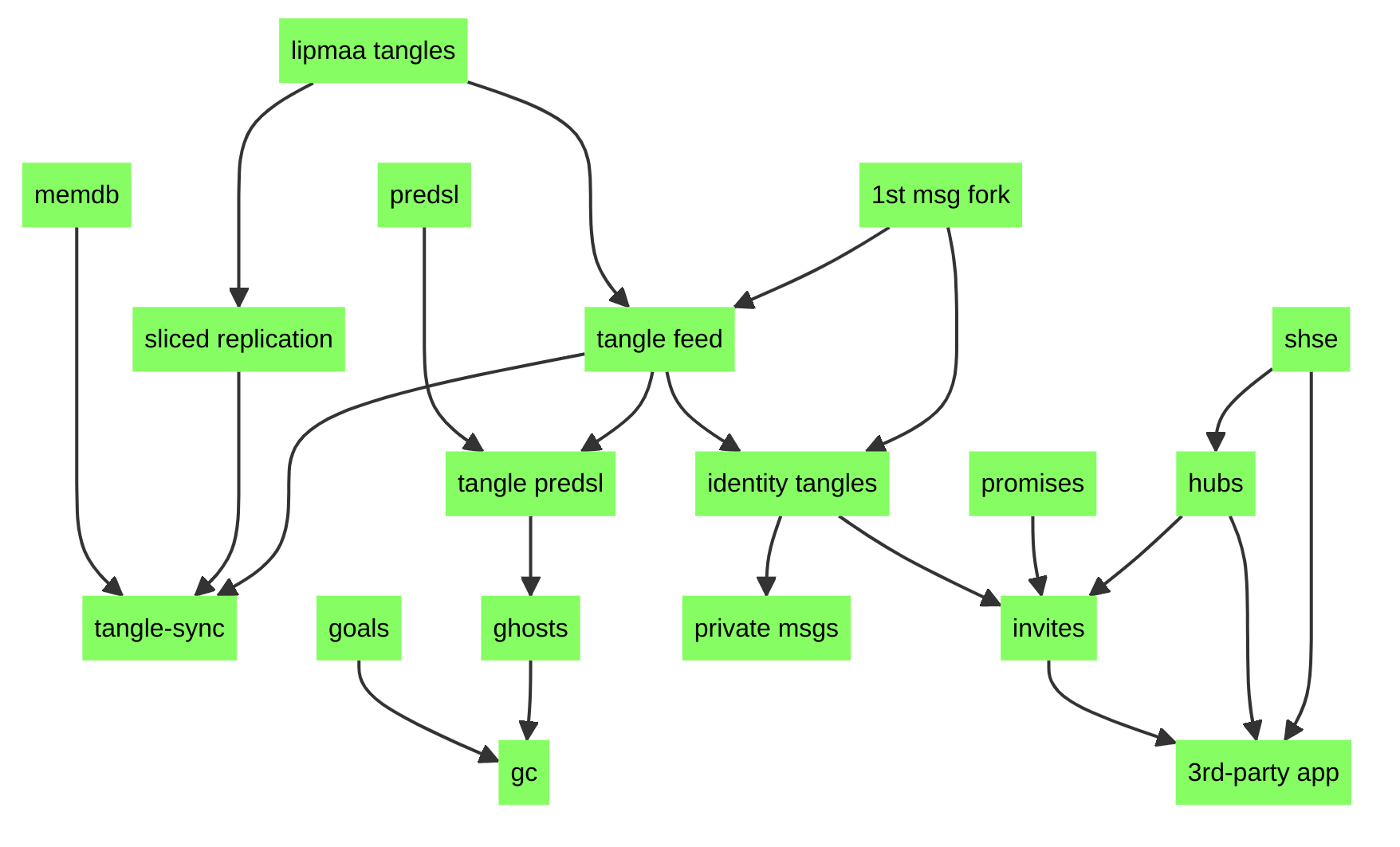
Now onto implementing, which will culminate in a big release of several things. Some of the implementation has been done already during the validation phase, so the following roadmap is partially completed. I could easily talk about each of these boxes, but I think that will be more interesting in the next newsletter update.
Last but not least, we are very fortunate that Mikey/Dinosaur (early SSB contributor, Sunrise Choir leader) just offered to help move PPPPP forwards, either with documentation or with a Rust implementation. I'm hyped!
– @andrestaltz